


AI is climbing to the top on the corpses of decrepit technologies
What do Google Translate, Wikipedia, and Photoshop all have in common?


To say that some people aren't happy with the rise of AI would be a diplomatic way of putting it. If any among you has a LinkedIn feed that doesn’t feature a breathless, apocalyptic screed against the sins of AI, I want to know your secret. Even people who claim to have once been optimistic about AI's humanistic potential have abruptly reversed their position.
The charges leveled against AI are legion:
It steals people's original creations to fuel its knowledge base
It makes stuff up, and every attempt to solve the problem makes it worse
It uses lots of energy
Your own personal data might end up in someone else's answer
Visual data sets may be tainted by kiddie prawn
It can't actually reason, no matter how much the cringey AI-bros insist to the contrary
It will ultimately destroy itself as it feeds upon internet information which was in turn based on AI-generated answers
Yet despite these shortcomings, AI was an unprecedented success. It reached 100 million users in just two months, compared to nine months for TikTok and a year for Google. Facebook was hailed as an almost overnight success in the Social Network movie, but that took FIVE years to reach 100 million. And, the way AI has completely captured all discourse relating to technology businesses also seems to be unprecedented. More companies are betting their entire future on AI right now than companies were doing with the internet itself in 1999.
And the internet, for all its flaws, was a pretty well-thought-out technology in 1999. It had grown organically and iteratively for the previous 30 years. It was a product of the best minds of the Cold War era, and was stress-tested for decades before hitting the mainstream. By comparison, today's AI is the creation of a ferret-faced dork who doesn't even understand his own product. It was scaled to the world so fast that it still has fundamental flaws from its earliest moments that haven't even been discovered yet. That doesn't stop every company on the planet from laying off half their workforce and sinking half their operating budget into becoming an "AI company". What gives?
GAI is the Mongol Horde
If you’re wondering how such a flawed technology became so economically influential in such a short time, it pays to know your history. The Mongol Empire should have never been able to conquer two thirds of Eurasia. The Mongols were a primitive horde of nomadic horse tribes that any reasonably competent state could have squashed. Unfortunately, reasonably competent states were in short supply in 13th century Central Asia.
The first victim of their westward rampage was the Khwarezmian Empire which was decadent, corrupt, and unstable. The feral Mongols were able to trample them with ease. The other neighboring countries were no better and either fell to the Mongols or surrendered to pay tribute. Each new conquest made the next one easier as the growing Mongol Empire became stronger, richer, and more technologically advanced. Once they reached the eastern edge of Europe, they were powerful enough to double back and conquer the mighty Song Dynasty in China. It would have taken just one halfway competent opponent early on, and we would never heard of Genghis Khan.
I imagine you can already see the parallels to the current tech landscape, but if not, let me spell it out. ChatGPT, as well as Claude, Perplexity, Midjourney, and all the others, were able to grow so quickly because they seized undefended economic territory. Each vertical they were able to occupy increased their valuation. Here are just a few examples.
Google
Google circa 2022 was (and remains) a hellscape of SEO trash, advertisements, and even censorship. Google's core strength was always "answering your question without friction", but a legion of bungling, upward-failing product managers at Google added more and more friction until it ceased to be useful. By 2022, Google's ability to find any information that wasn't phrased in a format that a searcher was likely to use would just never get found.
By contrast, ChatGPT - which had scraped the same internet that Google had - was able to get you to the information you were after no matter how you or the information's original creator worded it. There were no ads. There was no rambling SEO junktext. This quantum leap in convenience was enough to overcome the major reliability problems of the answers ChatGPT gave.
Wikipedia
Wikipedia has been ostensibly free of many of the problems that plague Google. Where Google indexes any page, no matter how redundant, poorly written, or inaccurate, Wikipedia only allows one page per topic, which is collectively kept free of redundancies, inaccuracies, and promotional crap. If you want to learn about the Tokugawa Shogunate or the atmosphere of Jupiter, you only need one page for each, rather than having to comb through dozens of pages on Google. And still, Wikipedia had become decrepit in many ways.
As a site run entirely by unpaid volunteers, the quality of Wikipedia's content is limited by the quality of those volunteers. A cabal of incel neckbeards and cringey weebs speaking in LOLcat-tinged Recession-era internetese assiduously gatekeep what information can go into Wikipedia, and in what form. Information deemed "not encyclopedic" by this army of dorks is swiftly deleted, no matter how much work went into adding it.
The “design by committee” approach to Wikipedia has led to a distinct lack of information hierarchy. The encyclopedia is rich in facts, but they are poorly organized and hard to get to. This has led to it becoming more of a fact dump than a vehicle for learning, let alone understanding. And any attempt at adding a “for dummies” section somewhere in the article so that laypersons can understand a complicated subject is just as swiftly put down.
Then, of course, there is the ideologically based censorship that plagues Wikipedia. When you have a relatively small number of contributors controlling the content on the site, you will have a non-representative demographic that decides the bias.
ChatGPT went after all of these weaknesses. In particular, early on, before the cheugy Karens of the internet shrieked for more censorship, ChatGPT was more than happy to provide you ANY information you asked for that it might have. It did seem to have a bias, largely based on the data set, but that could be overcome with the right prompts. And you could instruct it to reword any information so that a 5th grader could understand it, and it does a pretty good job of that. Now Wikipedia is directly threatened by ChatGPT, because the information that it spits out is entered back into Wikipedia pages, even when it's inaccurate.
Translation apps
Google and Apple Translate have been decrepit for years now. Neither of them lets you select which sense of a word you intend in your translation. If your input is simple enough, it will give multiple senses in the output field, like if you ask it to translate "beef" into Japanese, it will default to "gyuniku", which means "cow meat", and then offer the alternatives "bifu", or "ensei" (which means a grudge or complaint). But if you want it to translate a whole sentence whose meaning hinges on one or more homographs, you are out of luck. Here's an example:
"I saw her duck".
This sentence might mean that I saw her pet bird, or it might mean that I witnessed her crouch to avoid something. Translate does in fact give you a few interpretations of this sentence, but the first problem is that this functionality is completely hidden. You have to know that clicking on the translated text will open up a dropdown menu that looks like this:
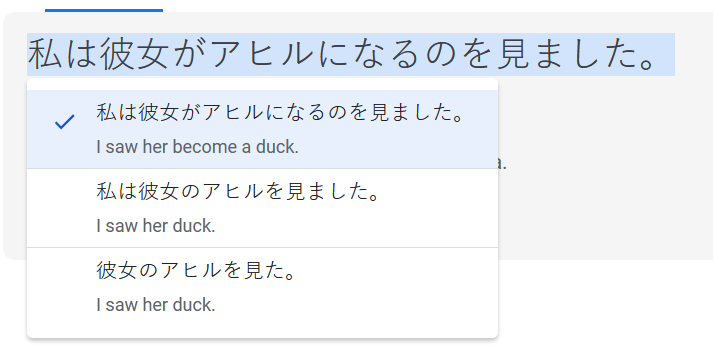
As you can see, that doesn't help anything at all. You have two translations that preserve the ambiguity we are trying to resolve, and a third, objectively incorrect translation. So Google fails miserably. Oh, and as it turns out, neither of the other two pertains to crouching.
Meanwhile, ChatGPT's LLM engine handles this ambiguity brilliantly. You only need to tell it what sense you were intending and it spits out an accurate translation that absolutely humiliates Google or Apple.
Visual design software
No use case of AI has resulted in more anguish than the generation of images, audio, and video. These engines are infamous for relying on the works of artists, assimilated into their data sets, without paying for them. While it's easy to understand artists' exasperation with this aspect of AI, it’s actually incidental in the grand scheme; AI could be made to operate ethically, paying creators for their works. And yet the rhetoric from artists goes far beyond demands to receive fair compensation for their work being sampled by AI. "Fundamentally dehumanizing" is thrown about with a biblical frenzy. Such artists see AI not just as a business risk but an existential threat to art itself.
Even the most cursory experiments with generative AI should dispel any notion of an artistic apocalypse. GAI cannot come up with new ideas. It cannot even create an idealized form of an old idea. What it does is regress to the mean of whatever data was fed into it, so that the results are inevitably derivative, banal, and just plain AI-looking. The only way to make an end product with any artistic merit using AI is to bludgeon it with so many manual prompts and inpainting that it starts to bear the unmistakable fingerprint of human intervention, restoring it to the domain of art. In other words, it takes an artist to get actual art out of AI.
So, if AI isn't creating art, then why are non-artists taking it up so eagerly, and why are artists acting as though AI means the death of art? It turns out that there is one answer to both questions.
While I could devote an entire book to the precise definition of "art", I think we can all agree that the transcendent aspect of art - the ability to evoke universal human experiences in the audience from highly personal creations - is separate from more teleological applications of constructed information.
Put simply:
Saturn Devouring His Son by Goya is art while the illustrations in an IKEA instruction manual are not.
Operation: Mindcrime is art while "Stimulus Progression" is not.
Spirited Away is art while the animations that illustrate how a product works on an informercial are not.
GAI will not give us the next Saturn, or Mindcrime, or Spirited Away (no matter how uncanny the Ghibli filter is). But it will upend the art-adjacent industry of visual communication. That’s because the tools for these more utilitarian purposes have remained stubbornly archaic. Here are a few examples:
Photo editing
If the average person wants to alter their appearance in a photo, either because they are using a dating app and they don’t photograph well, or because they are job seeking and want to confound ageist hiring practices, or any other number of reasons, their options prior to AI were limited. One can certainly accomplish a lot using Photoshop, but that presumes they have the technical chops to pull it off, and most people don’t. And most people also can’t afford to pay a professional photo editor.
AI can solve that problem. If you’ve got a bathroom selfie where you look good but you want to transport yourself to a more glamorous location, AI can do that (including changing your pose). If you look like you’re scowling in a photo and want to look more pleasant, AI can do that. The technology is still rough, but it’s evolving quickly. Adobe is slowly adding GAI functionality in this direction, but it is miles behind OpenAI.
Visual communication
In 2025, the world of information is so utterly saturated that it is becoming impossible to get noticed. Toxic algorithms are part of the problem, but ultimately, information overload is the real issue. There is no way around it: you have to shout to be heard nowadays. Using words alone won’t cut it, as I am all too aware, writing this piece. If you cannot convey your message as a meme or a cartoon, or some other visual media, you are mute.
While legacy tools like Bitstrips and meme generators enabled a rudimentary degree of creative power to enable the non-visually skilled to convey their ideas graphically, they are hopelessly primitive and their output tends to get ignored in media feeds. Meanwhile, ChatGPT is now able to render multi-panel comics that match the creator’s intent. These are not art in the sense that a high-end graphic novel is. Instead, they are semi-disposable wrappers around the creator’s idea, an idea that would probably be ignored if it were in text form.
Interface design
This one will hit close to home for much of my audience. Anyone who works in UX knows all too well the bias of the tech industry toward visual design over true UX. It doesn’t matter how brilliant of an information architect, or a researcher, or a semiotician you are. If you can’t draw a pretty picture, or make a cute UI design worthy of Drivvvel, you’re worthless, and you’ll be passed up for leadership roles in favor of some bananahead with ironic glasses. And that bananahead will go on to hire their fellow bananaheads.
This problem actually has deep roots, back in the skeuomorphic era where you had to be a full-on artist in order to make a competitive UI design. UX designers were massively disadvantaged. The advent of flat design ameliorated the issue (though at the cost of usability in some cases) but did not make it go away; the damage was done. Adobe could have developed features to put skeuomorphic design within reach of non-artists, but they didn’t. The same applies to Figma, which has shown more interest in serving semi-skilled pixel monkeys than actual UX people.
As a result, it is likely that neither Adobe nor Figma will be the UI design tool of the future. It is one more vertical in which GAI will become a dominant modality.

Legal and medical research
Within a year of the release of ChatGPT, there were already several cases in the news of lawyers who had gotten into trouble for citing nonexistent, AI-hallucinated cases in their arguments. If even a lawyer, who is trained in legal research, finds the existing legal research tools to be deficient enough to prefer a technology that infamously fabricates information with the confidence of gospel, then the lawyer isn’t the only one who should be fired.
Our government needs to answer this question: Why is there no publicly-available database of all case law, municipal, county, state, and federal? Why must someone pay money to a private company like LexisNexis to get access to piecemeal information generated by taxpayer-funded activities? It is an outrage that for some reason has gone unmentioned in this entire debate.
If even lawyers are resorting to ChatGPT in the hopes of efficiently locating legal precedent, then imagine how much more vulnerable the average citizen is. Legal services are obscenely expensive, meaning that only the worst people have access to adequate legal protection. If the average person wants to draft or review a contract, or if they want to assess the feasibility of a lawsuit, or defend themselves against one, they are either forced to hire a lawyer at great personal expense, or rely upon the limited legal information available to them online. And, even if they had access to the sum total of American case law, they would certainly not be able to find what they were looking for with the primitive search technology available prior to the advent of LLMs.
The same problem exists with medical knowledge. If, prior to 2022, someone wanted to research concerning medical symptoms, their first recourse would be Google, which would promptly spew a list of terrifying diseases, heavily biased toward “you’re going to die”. And that was when Google search wasn’t linking to outright falsehoods pushed to the top via SEO weaselry. This means that a person with medical concerns must see a doctor to get their questions answered. In America, that means spending money. In other countries, it means a long wait time, during which time they will remain anxious.
And if someone is dealing with a mystery medical condition that doesn’t fit into the handbook of accepted conveniently-applied diagnoses, they will have to build their own diagnosis from first principles. But, if you don’t have a medical degree, then getting to those first principles is impossible without a semantic search to translate the naive physiological vocabulary of the layperson into medical terminology. And the average medical textbook will present the information in a dense, academic format meant to keep outsiders out.
The fact that someone would gamble their health on an unreliable ChatGPT query is an indictment of just how bad medical information resources are. Not just in America, but everywhere.
Our government failed us by not making all case law available in an easily-searchable format so that everyone has equal access to legal knowledge—a fundamental civil right. And the whole world failed by not making the sum total of human medical knowledge available to all. This failure drives up healthcare costs in both private and public systems. And both failures created more opportunities for AI to gather up new users disaffected by the world’s galling information asymmetries.
Toxic gatekeepers
There is a common theme to all of the decrepit technologies that AI has conquered. That theme is entrenched interests who hold back the development of better technology.
Spammy websites based on SEO rather than quality rely on the janky Google search engine to stay alive. Google catered to these spammers, or at least failed to stymie them.
The aforementioned cabal of neckbeards would shriek and squeal whenever Wikipedia dared to introduce any improvements to the user interface. Even the seemingly non-controversial addition of page margins so that the text would not sprawl across a 1920*1080 monitor to the tune of 320 characters per line elicited Biblical meltdowns. So you can imagine the screaming and crying that accompanied Wikipedia’s plans to add a WYSIWYG editor so non-dweebs could contribute content too.
The users of creative software such as Photoshop and Illustrator - and for that matter, other software like video production, 3D rendering, music recording, web design, and more - have been remarkably tolerant of the terrible user experience of these programs, perhaps because they have a vested interest in the software remaining hard to use. They see their ability to navigate the bad user interface as a competitive advantage and don’t want to lose it.
Lawyers and doctors are unlikely to lobby for software that democratizes access to legal and medical knowledge, as it drives down the need for their services.
All of these examples make it more gratifying that AI will potentially render these gatekeepers obsolete. They held back progress for their own personal gain (or neckbeardy obstinacy) and, for their part, software manufacturers let them. And now they all face oblivion.
Now AI is everywhere. Congrats?
None of this is to say that AI was not inevitable. It is the natural progression of information technology, and LLMs are capable of doing things that no other technology to date can do. But, the explosive growth of AI has come with considerable costs, and society has not been able to acclimate to it as quickly as it is infiltrating every aspect of our lives. That part could have been prevented.
Each of the use cases that AI handles better than the legacy technologies is one more opportunity for AI to gain new users, and gain a greater share of their attention. If the relative advantage of using ChatGPT instead of Wikipedia, Google Search or Translate, or using Midjourney instead of a meme generator or Photoshop is not worth the cost of a subscription, or giving away personal data, then people wouldn’t bother, or they would adopt it more slowly.
Slower growth would have made these AI companies less financially viable, less likely to take in massive amounts of investment, and thus would have stunted their ability to completely warp the economy. In turn, that would have bought society more time to adapt. It’s even possible that the AI industry would have been forced to pivot to a more human-centric paradigm in which LLMs assist human work rather than attempting to replace it, an endeavour that is doomed to fail but is causing all sorts of problems in the meantime.
This article is not an endorsement of AI, nor is it a declamation. What it is, is an indictment of the incompetent product leadership that failed to safeguard economic niches from the relentless onslaught of AI growth. Fragile ecosystems are vulnerable to takeover by dangerous invasive species, of which AI is an example.
Does all this feel familiar?
This story has been told before. Consider the FAANGs. If you are unhappy that these corporations wield such a disproportionate influence over the world, consider how they rose to power.
Facebook devoured MySpace which had become a degenerate Gomorrah of spam and porn.
Google smacked down Yahoo, which was run by utter clowns and threw away every advantage it ever had.
Walmart basically drove business to Amazon by becoming the incarnation of everything people hated about pre-Recession American capitalism.
Apple won its position by wresting mobile phone design from the cellular carriers where other companies had failed (or not even tried), and the Android/iOS duopoly exists because BlackBerry and Windows Mobile completely fumbled.
It’s no news that supposed “leaders” don’t learn from history. But it’s remarkable just how badly our economic system has enabled such crappy companies to survive without more challenges. The companies waddle along, growing fatter and lazier, until a black swan event wipes them out and ushers in something new, but not necessarily benign. Anyone who focuses all their ire on AI without saving some for the companies who could have blunted its impact should probably just keep their opinions to themselves.
What comes next?
Speaking of MySpace, there’s another potential lesson here. MySpace may have been first to market, but they were not the winner. Facebook was able to learn from MySpace what worked and what didn’t work, and they used that knowledge to completely dominate the social media industry for 15 years. If you think that ChatGPT and MidJourney are the final word in AI, you haven’t been paying attention.
Remember, these particular technologies only came to dominate because the incumbents were so bad. They aren’t that great in and of themselves. ChatGPT and Midjourney are basically glorified parlor tricks. They are engineered to masquerade as artificial general intelligence, attempting to maintain the illusion at the expense of usefulness, all in order to appeal to callow manchildren and low-IQ execuchuds who confuse cutting costs with leadership. This artificial general intelligence theatre is going to come back to haunt these companies.
Consider the following:
GAI uses obscene amounts of electricity and huge data centers. This costs more money than they are bringing in. Eventually the investors are going to demand a return on investment, or they are going to pull out.
As lawsuits from aggrieved content creators begin to mount, the companies will buckle under not only the cost of payouts, but the ever-growing pile of restrictions they will need to build in to please those plaintiffs, which will infuriate paying users.
The computing power needed to run LLMs means that they cannot be practically operated on people’s personal machines, meaning they are subjected to censorship policies tailored to the lowest common denominator, and potentially surveilled by the companies as well.
And, most importantly, GAI’s vain attempts to cut humans out of the loop will be its death sentence. Without the ability to precisely control outputs, GAI will never be more than just a toy. But these companies lack any sort of expertise in manual controls
If the rise of AI demonstrated just how vulnerable to disruption Google and Wikipedia were, we may be gearing up for a sequel sooner than most think. OpenAI has poured a ton of money into developing the concept of LLM-based intelligence, and evidence is mounting that, as a path to AGI, LLMs are a dead-end. Meanwhile, the open-sourced Chinese startup DeepSeek has managed to achieve parity with ChatGPT at a fraction of the price. DeepSeek is a foreshadowing of things to come.
While OpenAI hemorrhages money into making LLMs superficially resemble human intelligence, it will only take one company employing much cheaper small or medium language models to plug them into human-operated software as assistants who enhance the capabilities of their human users rather than replace them, and people will quickly realize what a con GAI has been.
The question is, do the companies that enabled AI to walk all over them for the past three years have the spare IQ points in their upper echelons to counter-disrupt AI? The outlook is doubtful, given that companies like Adobe or Figma aren’t using AI to empower their users, but simply to make crappy imitations of MidJourney, and Google is creating a crappy imitation of ChatGPT instead of helping people to navigate the internet.
In a future article, I will be covering the ways in which language models could empower rather than replace human users. It will be interesting to see if any newcomers show up to completely clear the field.
The big tall lizard has made it this way
Excellent message! I was intrigued mainly by the intersectionality that AI has covered in such a short time, without considering subject matter expertise as part of the foundation but scraping on relevant content, meaning that opinion-based content is part of that formation. Politically speaking, it’s another way of distracting the masses from pursuing real and raw knowledge. You have all these bigoted companies competing to “who distracts the largest population?”
Excited to learn more and reflect on your writings! This one is 🔥.
Brilliant analysis and hopefully you can find an online media forum to share this more widely. The new media landscape is rife with political commentary. But it’s just blathering and mostly speculation, which of course it has to be. You’re offering analysis and action. I’m impressed as usual. Great work.